Appendix A - Introduction to The Shark Compiler
Unlike most database management languages, which execute a program one command at a time, SharkBase compiles its programs - that is, it processes all the commands before it begins to execute them. The Sharkbase "run-time compiler" converts the programmer's text file (the "program") into semi-standalone machine code. The run-time compiled program is more efficient and compact than a stand-alone executable since some of the backend machinery remains in the shark.exe file and doesn't need to be continuously re-loaded as the program runs. Regardless, the result to the user is the same - a much smaller, faster user tool. There is another major bonus in that the compiler functions like a "make" file which verifies the syntax and code of your program before it's handed over to the end user. The advantage to the programmer is that endless numbers of small related programs can be compiled together into one large program in a single step, like this brief (simplified) example from the Demo Programs. To compile four programs (e.g. VECTOR,FILTER,BIT,& LABELS) in one step, the programmer would create the following program 'frame' in SharkBase WRITE (or any other code editor such as NOTEPAD++) and call it, say, MENU.PRG:
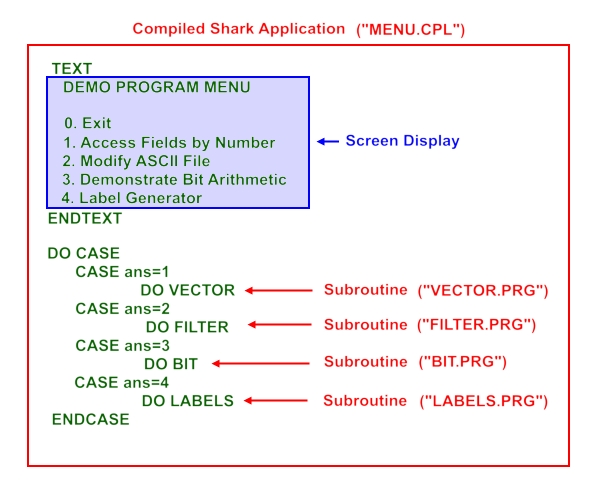
After compiling the MENU.PRG source, it becomes MENU.CPL. Even though the example is simplified for this discussion, you can see that the idea of compiling large applications from a series of small software subroutines is immensely convenient for the application developer since the subroutines can be run and debugged individually before compiling the entire set as "MENU.CPL". For this (and other) complete examples see the DEMOS file folder included in the Downloads Package.
Creating & Compiling a Program
As in most high-level programming languages, SharkBase programs are compiled fom a source script with the ".PRG" extension, rather than interpreted like BASIC and dBASE. An interpreted language reads each line of program script every time it is encountered, decides or interprets the script, gathers the components together, and then performs the script as written. A compiled language reads a command just once, translates (compiles) it into a series of instructions in machine language better suited for fast machine execution; these translated instructions are compiled into a machine language file. When the program is run, the compiled machine-language instructions are executed. This explains why compiled programs execute much faster than interpreted programs. In SharkBase, you normally compile your program script (the ".PRG" file) into the finished ".CPL" application before putting it to work. It is actually possible to load and run the ".PRG" script without compiling if you are curious. SharkBase may look similar to an interpreter while compiling on-the-fly in load-and-run mode. It is actually doing exactly the same job as the compiler, except that it immediately executes the compiled script; when execution ends, no compiled version of the script is kept. Shark doesn't need the source script to run the final application, only the finished CPL file. Normal SharkBase compiling uses the COMPILE command (example: "COMPILE DEMOS.PRG") and saves the compiled version of your program script into a file with a CPL extension ("DEMOS.CPL") , but your program is not immediately executed. Though DEMOS.PRG can be executed in load-and-run mode without compiling, this is a convenient place to compile. Just enter COMPILE DEMOS.PRG (or simply "COMPILE DEMOS") at the 1> SharkBase prompt. If there is no error, SharkBase returns to the prompt; otherwise, SharkBase prints an error message and prints the line containing the error. Press <Esc> and return to SharkBase WRITE to correct the error; then recompile the program.
Although there are no data files used in the program above, most SharkBase programs will naturally use them. When your program is compiled, your data files must be present so SharkBase knows what fields to deal with. SharkBase does not need any actual records in the data file at this point, only the data file structure laid out with the CREATE instuction as in "CREAT CLIENTS.DBF" or "CREATE ORDERS.DBF".
As you proceed with developing your applications, SharkBase provides a number of useful commands to help you discover and eliminate errors in your programs:
1. SET LINE ON to have the line number of your program encoded into the compiled form. This is the SharkBase default. It is necessary if you want SharkBase to highlight the program line with your error in it at execution time.
2. SET ECHO ON to have the compiler print each line it processes on your screen. Echo should be used only if your program dies without an obvious reason. The echo shows the exact line causing the error, together with up to 20 preceding program lines.
3. SET DEBUG ON activates the printing of messages and expressions during execution (helping to debug the program) placed in the program with the DEBUG command. In addition, it always forces SharkBase to compile and run the PRG file, rather than running a pre-existing CPL file.
4. STATUS is going to be one of your best fiends. When STATUS (or STAT) is used, almost everything you want to know about your data files, index files, memory, and setting is presented on the screen in a series of organized pages. Programmers may use the STATUS command several times in a program to halt execution and provide a "snapshot" of the current situation. After the program is debugged, remove all the STATUS commands. Note that the output of STATUS cannot be sent to the printer; you can, however, print your entire screen at any time with <PrtSc>.
5. LIST MEMORY is actually the final part of STATUS, and may be used the same way. Note, however, that LIST MEMORY does not halt execution during a program. Therefore, to see the output of this command, either follow it with a WAIT command, or precede it with SET PRINT ON and follow it with SET PRINT OFF to capture the output on your printer.
6. LIST SYSTEM can be used at any time to obtain the current contents of your system variables, including :PICTURE, :COMPANY, ;DATE, :TITLE, and your function keys, all of which were discussed earlier.
DO and CHAIN
Once compiled, your demo program may be executed with the command DO MENU or CHAIN MENU, whether at the SharkBase prompt or in another program.
As a programmer, you will create numerous programs for both simple, repetitive jobs and for much more complex tasks. Programs may be executed (run) from the prompt line by saying DO <file>, where <file> is the name of your program file, with no extension. If a compiled program exists (with a CPL extension), it is executed; otherwise SharkBase uses your original program with its PRG extension, and compiles and runs it on-the-fly. But, of course, programs can also execute programs. In this case, you have a choice of execution modes:
1. Programs can DO other programs as subroutines, from which execution can return to the calling program. When you DO a program, all memory variables and data files remain unchanged and are available to the subroutine.
2. Programs can CHAIN to other programs. A chained program begins with a clean state, with no variables in memory (except global and system variables; see Tutorial Chapter XI) and no data files in use. Furthermore, the chained program cannot tell where it was called from, so it can never RETURN; it must either CHAIN back to the program which chained to it, CHAIN to another program, CANCEL, or QUIT.
Programmng Pitfalls
This section calls your attention to some aspects of SharkBase programming that you might otherwise overlook.
1. CPL is executed if found. SharkBase will not execute a program in a file with a PRG extension when a file exists with the same name and a CPL extension. Keep this in mind, or you may be fooled into thinking you are running one version of the program while you are actually running another. Say, you made an error and your program would not compile. You go into SharkBase WRITE, fix the error, and then DO the program again. There's no sign of the changes you made. You have been caught by the CPL file that was opened on your disk. Either delete the existing CPL file or recompile the program; then DO it. Remember: you must create a new CPL version by recompiling your program before trying to DO it again.
2. Data files and subroutines must be present You must remember that all data files your program uses and all subroutines your program calls with DO must be present when you compile the program. The data files can be empty, but they must be present. In addition, you should recompile any program that uses a data file whenever you change its structure.
3. COMPILE can be executed in a normal program, but remember it always does a CLEAR first. Therefore, no memory variables or data files survive the COMPILE command. The COMPILE instruction must be performed using your fresh PRG program input source file, not from within a running program.
The Shark Compiler
Database programs are a common business tool. A program such as Microsoft Excel is a simple, but very slow, data-processing tool. Dedicated single-purpose data-processing tools like TurboTax or QuickBooks are high-speed database applications. They all have the same underlying database structure. Excel and Turbotax, for example, can open and read any Sharkbase data file. SharkBase is the same under the skin, except that it can be used to write ANY type of data-handling application, not just tax returns or check-book records. Compiling is a major reason why SharkBase applications run so much faster than other data tools such as spreadsheets and simple dBase applications. Most of the time, the compiler will be invisible to you. However, compilation presents some advantages and restrictions that are unique to SharkBase, and we'll outline these in this appendix.
A.1. What Happens At Compilation:
Before a program can be executed, SharkBase must perform two tasks: First, the program script itself must be translated into compile form. In compiling a program, SharkBase converts its commands into hardware code that is very speedily executed by your computer. In command lines with "macros" (similar in principle to C-language references or pointers), only the command verb is coded; such lines load the final data later, when they are executed.
Why Not an EXE File?
Many compilers for computer languages produce a single file with the EXE extension; such files can be run without the compiler's presence. Why doesn't SharkBase produce such compiled programs?
Most compilers are made up of two parts. First is the compiler itself, the program that does the translation. Second is the subroutine library; most compiled commands make a number of calls to this library.
At compilation, the compiled program is "linked" with the library (or with the part that is needed).
SharkBase, by contrast, is the actual run-time library. It doesn't link the compiled porgram to a separate library, since SharkBase itself acts as the library.
This has three major advantages:
1. The compiled programs can be far smaller, since none of the library is
attached separately to each program.
2. It is far easier to develop an application a small step at a time, since adding
functionality to any one program script probably has no effect on those already
completed.
3. SharkBase has the compiler present at all times to evaluate and resolve
macro references/pointers during runtime, since macros are left uncompiled during
compile-time. (A Shark "macro", e.g. "&name", provides whatever name is stored at that location). Whenever Shark encounters a macro in a running program,
SharkBase accesses the compiler, translates the macro, locates the contents, then continues execution.)
Second, SharkBase has to prepare the computer's memory in order to keep track of information that the program uses and manipulates. The state of this memory space at any given time is called the environment.
SharkBase always compiles a program before executing it. If you run a program in its text (PRO) form, SharkBase compiles it on the spot. The PRG file on disk is unaffected: if the program fails, you can still edit (or debug it) as needed.
Compiled Programs
The COMPILE command translates a named file with the PRG extension to a compiled program with the same filename, but with the extension CPL. This new, compiled file will load and begin execution more quickly. However, the compiled form in the CPL file can't be edited directly. If you find an error in the program, edit the PRG source file, then compile it again.
SharkBase always attempts to run the compiled version of a program first. It will run the PRG source file only if it finds no compiled CPL version on the disk.
You can also compile a list of programs; see the COMPILE command for more information. the COMPILE command in Section 4.3.
In some ways, compiling is a "dry run" of the program: the compiler opens and closes the named data files, creates all of the memory variables (but types and values are not attached), sets up internal tables (stacks) for nested command structures, and tests expressions for validity (for form, not for variable types). The errors found at this stage are called compile-time errors.
It's important to remember that compiling a program is not exactly the same as executing it; rather, it is the preparation for speedy execution. Certain types of errors do not appear at compile time. These errors are called run-time errors. Most often they involve variables of the wrong type.
Compile-time errors are always reported by SharkBase with the line number. Run-time errors report line numbers only if the line numbers are compiled into the program; this is accomplished with the SET LINE ON command (the default).
To understand the effect of the compiler on programs, it helps to know something about how the compiler reads the text of a program and about how SharkBase manages memory - its environment.
A.2. SharkBase Environment
The term environment refers to the current arrangement of memory, SharkBase's "workspace." This is where SharkBase keeps track of all of the data files and variables being used, the program being executed, and other special settings. When Shark loads in the vDOS emulator, it loads its components as follows:
The SET File
SharkBase always runs under DOS, in what is left of the computer's memory after DOS itself (and possibly some memory-resident programs and/or a network) are loaded. If total memory is 640K, anywhere from 350K to 625K will be available to SharkBase.
SharkBase, however, allows high-memory to be limited to as little at 48K, and to allocate up to 32K for loading assembly-language modules assembled into binary files and executed from within SharkBase.
Under MS-DOS 5.0, the memory map looks like this when Shark is fully loaded:
Top of MS-DOS memory
1. External high memory (used by RUN command)
2. BIN file space if any (BINSPACE=)
3. Internal high memory (MEMORY=)
4. Data space (64K)
5. SharkBase (335K)
6. Memory-resident programs, if any (unload if necessary)
7. COMMAND.COM/Operating system (12-80K)
Bottom of MS-DOS memory
When running under an MS-DOS emulator like vDOS, the memory map is similar, in this example showing a 176K block of free memory useful for running other applications at the same time.

The special files called SHARK.SET and SHARKN.SET for the single-user and network versions of SharkBase respectively provide control over levels 2 and 3 (see these commands in the Reference Guide), while the FIELDS= command affects the allocation of memory within level 4. (NOEFFECTS is used to suppress screen and sound effects, and has no effect on the environment.)
What is the Environment?
SharkBase takes control of all memory in levels 2 through 6, an area generally termed the "environment." Much of the environment remains constant, but we are concerned primarily with the items that can change.
Therefore, you can think of the environment, in part, as all data files that are currently open (with their respective fields) and the file numbers assigned to them. Changing the set of open data files produces a different environment.
For example, these data file actions serve to establish and change the environment:
1. Opening a data file (with the USE command).
2. Assigning a file number to a data file (SELECT, USE).
3. Closing a data file (CLOSE, CLEAR).
4. Changing the structure of a data file (MODIFY).
5. Opening or closing index files (USE, SET INDEX).
(To see a "snapshot" of the environment, give the STATUS command. This displays information about the current state of open data files, SET switches, and memory variables.)
Memory variables, too, are part of the environment, and the environment is affected when you create a new memory variable (with =, STORE, et al; see "Variables" in the Topical Reference) or release an existing one (RELEASE, CLEAR). The data-type and contents of the individual memory variables are not significant to the environment; what is important is the order in which they are created.
SharkBase keeps track of the data files and memory variables by creating reference tables in memory. These tables are described in more detail later in this section.
Finally, there are specific environmental commands: the SET commands (SET ... TO) and SET switches (SET ... ON/OFF). They are used in conversational mode, in programs, and in the configuration file SHARK.CNF to customize SharkBase. For explanations of the individual SET controls, refer to the Alphabetical Command Reference.
The Configuration File
The configuration CNF file is a program that, if present, is automatically executed when you start SharkBase from DOS.
SHARK.CNF can contain most commands. Its primary purpose, however, is to configure SharkBase's default settings to your computer and to your applications. Typical commands in the configuration file are the SET commands and switches, in particular, SET DEFAULT, SET MEMORY, and SET FIELDS; values assigned to system variables and function keys, in particular, to :COMPANY; also, the structure FILES ... ENDFILES normally appears in this file.
A.3. SharkBase Memory Use
The table in Section A.2. illustrates how SharkBase uses memory (RAM) space:
SharkBase itself utilizes about 200K of memory. To maximize speed, the EXE program is not overlayed so it all goes into memory at one time ... an advantage of being kept "lean and mean."
Data Space
The following table illustrates the use of the 64K of data space reserved by SharkBase:
----------------------------------------------
DOS work space (for Read buffers)
----------------------------------------------
Work space (about 25K)
----------------------------------------------
Includes:
Program area
Data Records (data file buffer)
Indexes
Relations
Limit
----------------------------------------------
DOS stack
----------------------------------------------
Internal data space (fixed)
----------------------------------------------
Data File Table
The data file table tracks all open data files. It includes an entry for each field of each data file in use, describing the field, and a pointer (a number indicating location in memory) to the data file buffer for the contents of the field.
Any time a data file is opened, a memory area, called a buffer, is set up for it, the size of one record.
The size of the data file table is 320 fields (unless changed in the SET file by a FILES= command in SharkBase). For instance, the commands:
USE employee
USE#2 invty
USE#3 credit
USE#4 supplier
will set up a data file table like this:

Now if you close invty.dbf:
1>CLOSE#2
the table becomes:

leaving a 12-field empty space. When the next file is opened, is goes into the vacant space if it has 12 or fewer fields, otherwise it goes after SUPPLIER in the left-over unused file table space:
Now if someone is not paying attention, and asks Shark to "USE#2 ORDERS.DBF", Shark will try to accommodate the request to squeeze the 18-field orders.dbf file in the empty 12-field #2 space in the file table, thus setting the program up for mangled data files.

This is not a problem if ORDERS.DBF is 12 fields or smaller. Otherwise, the programmer should see this coming and instead request to "USE#5 ORDERS.DBF". It's a simple move to re-open all the files at any time by doing:
USE employee
USE#2 invty
USE#3 credit
USE#4 supplier
USE#5 orders
This resets the file table, and everything remains orderly! The compiled Shark program is fast enough that this is not even noticed by the user.
The above explanation should show the process yielding either a continuous block of smooth-running data fields, or a gap-filled hodge-podge of data. A carelessly assembled block of data with overlapping data fields will result in random data crashes with no clear error message(s). The principle rule should be to assemble the data files at the beginning of the program, and open and close data files carefully. There is no real need to be opening and closing data files randomly. There is plenty of space to develop complex, speedy applications within the above structures. If space becomes too crowded, it's a simple task to close all data files and start a fresh sequence without creating any speed-bumps.
The only other consideration when opening and closing data files in an application will be when writing networked applications. The safest operation, of course, is working with "read only" data files all the time. Nothing changes! However the nature of business is that files will be opened ("write" mode) for writing, and closed ("read" mode) for reading only. When there's many users, it will be necessary to REALLY close (i.e "LOCK") a file for a few seconds while a busy "write" with a waiting line is underway in order to protect against accidents when users are in a hurry. The point of this is that opening and closing data files in this manner doesn't affect the data space as long as the files remain in the starting sequence.
USE employee READ
USE#2 invty WRITE
USE#3 credit READ
USE#4 supplier READ
USE#5 orders WRITE
In this setup, all users can view all files at any time,whether READ or WRITE. If one of the system users wants to add an order to #5 (i.e. needing to add a new order from a customer), you would add the instruction:
USE#5 orders LOCK
to prevent other users from interfering when updating the ORDERS file, then restore it to READ status with a
USE#5 orders READ
immediately after adding the new order, thereby allowing the other users to view the ORDERS file again. Doing this doesn't disrupt the file table since the sequence of the files in the file table is unchanged.
Data Records
An index file uses a buffer of about 256 bytes. Each relation established with SET RELATION, each filter set with SET FILTER, and each limit set with LIMIT or SCOPE commands, takes 128 bytes.
Program Space
Programs load and compile in this space. Certain other commands affect the amount of memory actually available for programs. The REPORT command needs about 5K, so programs that use REPORT must be 18K maximum. The number of bytes available in the program space is given by the SPACE() function and also by the STATUS command.
The Internal Data Space
The internal data space reserves all the memory Sharkflase needs for internal variables, stacks, and so on. The size of the internal Sharkflase data space is fixed by SharkBase; it may change from version to version. Since programs compile right on top of this space, all user programs may have to be recompiled whenever a new version of SharkBase is used.
The internal data space contains a number of important tables.
The Memory Variable Table
This table has 128 entries. It describes all the memory variables in use. For each variable, it contains a pointer (a number indicating location in memory) to the contents of the variable. The contents could be in the compiled text (some strings), in the memory variable storage table, or (for matrix variables) in high memory.
The Memory Variable Storage Table
This contains the contents of those memory variables not in the compiled text or stored as matrices in high memory. It is 4K in size.
Stacks
Used during compilation and program execution, stacks are internal tables that keep track of the nesting structures IF and DO WHILE and DO commands. Various stacks are utilized by SharkBase. If too many levels of nesting are used, and one of these stacks runs out of room, an error message is issued.
Internal High Memory
The use of Internal High Memory is illustrated in the following table:
{External high memory)
High—end of internal high memory
---------------------------------------
Matrix variables
---------------------------------------
Index buffers (16K—64K)
---------------------------------------
FILES table
---------------------------------------
screens 2, 3, 4 (4K each)
---------------------------------------
Temporary storage
---------------------------------------
Command lines
---------------------------------------
Low~end of internal high memory
(Data space)
SharkBase uses 128K of high memory as internal high memory (unless MEMORY= is used in the SET file; see "External High Memory", below)
800 bytes are reserved for command line storage. Index buffers take a minimum of 10K; ordinarily, they take half of internal high memory, to a maximum of 64K.
The FILES table is created from the FILES ENDFILES structure in the SHARK.CNF or SHARKNET.CNF file.
Each matrix variable may occupy up to 64K of memory. There can be at most 20 matrix variables in use at one time.
The STATUS command displays the number of bytes left in high memory.
External High Memory
External high memory is essentially whatever is left over after SharkBase takes the amount it needs plus as much internal high memory and BINSPACE is requested or available, whichever is less. To maximize external high memory available to the RUN command, SharkBase users can reduce the amount of internal high memory requested; example MEMORY=64.
A.4. Modules and Environment
The SharkBase compiler treats each kind of module (stored command sequence) differently. The differences lie in the way each module type interacts with the environment.
Procedures
A procedure is defined in a PROCEDURE ...ENDPROCEDURE structure, and called (executed) by the PERFORM command. A procedure is compiled only once, the first tine it is called. This means that if the procedure is sensitive to the environment - that is, if it refers to data files, fields, or memory variables - then it can only be called into the same environment as when it was compiled. If the environment changes - i.e. if the data file numbers are reassigned or memory variables released — then the prceedure must not be affected by these changes, it must not refer to the changed part of the data file table or memory variable table.
Subroutines:
A subroutine is a command sequence stored in a separate program. It isn't compiled as a separate file, but rather as part of the main program that calls it with the DO command. (See, however, section A8 "Compiling Multiple Subroutines") In code terms, the compiled subroutine becomes a part of the compiled main program; in execution, it becomes an overlay. This means that when the execution reaches the subroutine, the main program is exited; its status at this point recorded. The compiled subroutine is brought in; it overwrites (overlays) the main program. When the subroutine is exited, and the main program is brought back, its status recovered, and emcution continues. Unlike a procedure, a subroutine is compiled each time is called. If there are five DO commands that call single subroutine, then the subroutine is compiled five times - each time with the current environment - into the main program. To avoid unnecessary compilations of subroutines, place them in procedures. For instance, the subroutine SUMMING is used with two different environments 15 times in a program. Using DO SUMMING 15 times would result Ina compiled program that is far too large. Instead, define two procedures:
PROCEDURE summing1 DO summing ENDPROCEDURE PROCEDURE summing2 DO summing ENDPROCEDDRE
Give the command PERFORM SUMMING in the first environment, and PERFORM SUMMING2 in the second environment. This will make the compiled program substantially smaller.
Chained Programs:
The simplest kind of script module is a "program". One program can be executed from within another using the CHAIN command. When this command is used, the environment is cleared and the new, chained program begins execution with a "clean slate." All data files to be used must be re-opened and memory variables redefined. Memory variables (but not matrices) can be passed between chained files by using the GLOBAL command; see GLOBAL in the Alphabetical Command Reference. A program called by CHAIN dces not return to the calling program. Any program may be chained to any other; a program may even be chained to itself (for example, in an ON ESCAPE structure, CHAIN can be used to re-start the current program).
A.5. The Compilation Process:
Some aspects of compilation have an impact on SharkBase programming. This section gives you an overview of the compilation process.
Steps Compiling the Program:
In compiling a program, SharkBase analyses the text of each command line, and rewrites it into a language that can call up SharkBase's own internal functions as they are needed.
SharkBase is a one-pass compiler. This means that SharkBase compiles the command lines one at time.
Steps of compilation:
1. The compiler replaces all memory variables by pointers to the memory variable table. At compile time, the type of the variable is not entered into the table, only the name and the order in which they are defined. This should he kept in mind when using the commands; RELEASE, CLEAR, RESTORE FROM, GLOBAL, CHAIN, and DO. Note that all memory variable files (MEM files, created with SAVE TO) have to be present at compilation when a RESTORE command is used.
2. The compiler replaces all fields by pointers to the data file table. In the data file table, there are pointers to the data file buffer for the current contents of the fields. This should be kept in mind when using the commands USE, SELECT, and CLOSE. For instance,
USE CUST
cannot be compiled unless the CUST.DBF file is present. Of course, CUST need not have any records - just a structure. See also "Compiling and Data Files" later in this Appendix for alternate ways to refer to data files.
3. The commands are rewritten into SharkBase's own internal language. The internal commands mostly call functions in SharkBase. When a macro is encountered, the command verb is coded, and the compilation of the line is put off until execution time. Pointers are placed in compiled command lines to indicate the beginning or end of a control struclure, or of some part of the control structure. For instance. each CASE includes a pointer to the line containing the next CASE; each ENDREPEAT includes a pointer to the REPEAT command that begins the structure. More specifically, when SharkBase encounters the command
IF cond
where cond is a logical expression, it puts the location of the compiled line on the IF stack. When ENDIF is encountered, this location is pulled off the IF stack and the location after ENDIF placed into the IF line. So if cond is false at execution time SharkBase knows where to jump to go beyond the command sequence it does not have to execute. This is what is known as forward referencing
.Forward referencing contributes significantly to SharkBase's speed advantages over other database languages.
Forward Referencing in Action
Here's an example of how fast this makes SharkBase compared to dBase or Clipper. Consider the following program:
STORE 0 to count STORE 1 to a DO WILE count <500 DO CASE ******************* 1 CAS 1=2 STORE A to dummy STORE A to dummy STORE A to dummy * each CASE consists of above STORE line 50 timee ****************** 2 CASE * total of 5 cases, all false * all with same line 50 times. CASE 1=2 STORE a TO dummy STORE A to dummy ENDCASE STORE count+1 to count ENDDO
This program,which would take 267 lines when all the repeated commands are typed out) does not do much. It repeats 500 times, using the DO WHILE ...ENDDO structure (rather than REPEAT... ENDREPEAT which is not a command of any of the known dBASE languages) and the DO CASE ... ENDDO structure. There are 5 CASES, each one with a false expression as a condition, so none is ever executed. Each CASE is 50 lines long; since the lines never get executed it does not matter what they contain. The SharkBase version was compiled first and the CPL file was run, beating the fastest dBASE version by 100 to 1. Forward referencing clearly provides a significant improvement in processing speed. And, although this program is for testing purposes only, its structure is very similar to many business programs. For instance, a payroll program with 5 different types of employees would have this type of structure.
5. Procedures are compiled wherever they are first performed.
6. Subroutines are compiled into the main program with each calling DO command: a subroutine called three times is compiled three times.
A.6. Compiling and Data Files
Several aspects of using data file references within SharkBase programs require special attention. These are covered in the following few sections.
Conditionally Opening and Closing Data Files
SharkBase compiles all command lines whether or not the conditions controlling their execution are true (that is, whether or not they are ever executed when the program is run). At compile time. SharkBase cannot know the status of all conditions, since conditions may be decided by the user or the program while it is running - not in advance. This compilation process has implications that need to be considered when opening and closing data files in conditional structures. Take a simple example of two data files, T1 contains the field VAR1 and T2 contains VAR2. Now, say we try to use the following command sequence:
USE temp2 ;temp2 is opened IF cond USE temp1 ;temp1 is opened ? var1 ELSE ? var2 *temp1 is still open ENDIF
This command sequence, which would run perfectly under dBASE, fails to compile in SharkBase. Here's why:
When SharkBase compiles the IF structure, it does not know whether cond will be true or false at execution time. So, when the next command line opens data file temp1 (thereby closing temp2) the SharkBase compiler performs this operation.
However, in the ELSE clause (which at execution is performed when the condition is false), the program looks for the field VAR2 (which is in the now closed data file T2) the result is a compiler error. Note also that if the ELSE clause didn't refer to T2, any command following this IF structure that expected T2 to be open would create such an error.
Because of the compiler's way of carrying out commands, it is recommended that you open and select all data files at the beginning of a program, if possible. Limit (i.e. avoid if possible!) the use of the commands USE, CLOSE, RELEASE, CLEAR, and RESTORE in conditional command structures.
If you must include commands such as USE in a DO CASE or IF structure, include one at the beginning of each case (including ELSE and OTHERWISE), and one after the END command:
IF <cond> USE <filename> <command sequence> ELSE USE <filename> <command sequence> ENDIF USE <filename> . . . DO CASE CASE <COND> USE <filename> <command sequence> CASE <COND> USE <filename> <command sequence> OTHERWISE USE <filename> <command sequence> ENDCASE USE <filename>
Note that such programs also run under dBASE. In fact this technique is good programming practice in either SharkBase or dBASE, since it makes data file choices more explicit.
Referencing Unknown Data Files
To open data files and use field references in a program, it's essential that the data files referred to be present at compile time. Data files must be available on the path specified (either with a FILES structure. with SET DEFAULT, or with USE <drive letter>: <filename>.
(Since index files are mot opened at compile time, they need not be present when compiling) If a data file used by a program is unavailable or unknown at compile-time, follow one of these suggestions:
1. If the name and structure are known, but the file doesn't exisk create an empty data file with the name and structure of the missing data file. Remember, the compiler doesn't read data - it only checks to make sure the proper fields are present for the commands to be executed.
2. If the name and structure of the data file are unknown (That is, if these will be supplied by the user at execution) open the data file with a macro in the USE command, and use macros in place of any field references within the program.
3. As an alternative to using macros in place of field references. you can make sure that each command line referring to a field in an unknown data file contains at least one macro. Including a macro defers compiling of a command line until execution, when the structure of the data file will be known.
4. If the structure is known. but the name is unknown (if it will be supplied by the user at execution), give a USE command with the COMPILE keyword. USE.. COMPILE lets you open a data file with an identical file structure for compile-time references. A second USE command containing a user-supplied file name in a macro, opens the desired file at run-time (i.e.. upon actual execution of the program).
The following two USE commands coeist peacefully within the same program, the first working at compile time, the second at execution.
USE#2 inven COMPILE USE#2 &filename
Here's how this sequence works: At compile time ...USE#2 inven COMPILE tells the compiler to open the data file INVEN.DBF as a surrogate for file#2. The structure of INVEN (field names, field types. etc.) is used wherever file#2 is required later to to be run in the program.
USE#2 &filename is only partially compiled (as are all commands with macros).
At execution ...USE#2 inven COMPILE is ignored.
USE#2 &filename is used, with the user supplying the filename for this data file. The file structure (field name, field types, etc.) of this file must be the same as that of inven.
This is useful when several people use the same program to access data files with the same structure, but different file names; for example, if several sales entry clerks have their own transaction files to which they enter orders.
Here is a program that uses macros to choose the correct file to work on at runtime:
USE customer compile ;this could be any file name IF cond mfile='inven' ELSE mfile='orders' ENDIF USE &mfile ;the file you want at runtime is opened
Commands That Close Data Files
Another set of commands to be careful with are those used to move data from one data file to another. These are APPEND FROM COPY, COPY STRUCTURE, POST, SORT, and TOTAL. They are alike in that the data file named in them is left closed once the command is executed.
Actually what happens is this: when SharkBase encounters one of these command, it looks for the named file. If the named file is open, it is first closed. Then it is opened as a temporary, internal data file. Once SharkBase finishes executing the command, the internal file is once again closed.
As a result, you must reopen any data file named by one of these commands if subsequent commands refer to fields in this named data file.
Here is a command sequence that uses a temporary data file (tempcust) to add customer records. When it finds there are no more additions to make, it appends the temporary data file to the main data file (customer):
USE#2 customer ;Opens customer SELECT 1 USE tempcust ;Opens tempcust ZAP DO WHILE T <command sequence> ;Commands for record entry IF name =' ' ;Typical way of ending program SELECT 2 USE customer APPEND FROM tempcust ;Copies from tempcust to customer, ;leaving tempcust closed CLOSE ;Closes customer SELECT 1 ENDIF <command sequence> ;These commands refer again to tempcust ENDDO
The flaw in this command sequence should be clear from the above discussion. Since APPEND FROM names tempcust, this data file is closed and then reopened as a temporary, internal data file. As a result, subsequent references to a field in tempcust (in the command sequence following ENDIF) will cause compiling to cease with this error message:
"2. Variable not found."
This sequence is fixed by simply inserting the command "USE#1 tempcust COMPILE", as follows:
. . . SELECT 1 USE#1 tempcust COMPILE ENDIF <command sequence> ENDDO
Compiling and Data Files
All the commands listed above (APPEND FROM COPY, COPY STRUCTURE, POST, SORT —and TOTAL) have the same effect and require a USE ... COMPILE command as above if fields within the named file are referenced later in the program.
A.7. How SharkBase Reads a Command Line
In SharkBase, a command line is defined as the text from the beginning of a line up to a carriage return (indicating the end of the line) or a semicolon. A semicolon followed by a comment is ignored by the compiler; a semicolon followed by a carriage return (ENTER) indicates that the command line continues in the next line.
Analyzing a Command Line
The compiler analyzes the command line beginning with the first wont It checks the first word by taking the following steps and acts on the first case that applies:
Step 1. Is the first word a ? or ?? command? Step 2. Does the first word contain a command redirection (e.g., in USE42)? Step 3. If the first word is a number, then the line is rewritten as a GOTO command. Step 4. The first four letters of the first word are looked up in a table of command-verbs. Step 5. If the first word is followed by an equal sign (=) or an open square-bracket (I), the line is rewritten as a STORE or REPLACE command. (Note that step 5 overrides the decision made by step 4; see example below.) Step 6. If Steps 4 and 5 both fail, SharkBase displays an error massage. Step 7. The line is checked for a macro (if a macro is permitted for the command identified in Step 4). Step 8. SharkBase jumps to the compilation routine of the command found in Step 4. Step 9. If the first word is SET, Sharkaase checks whether it is a setting command (e.g., SET ALTERNATE TO, SET COLOR TO; these are separate commands) or a switch (e.g., SET ADD ON, SET BELL OFF; these are all different parameters of a single command). If no valid command or parameter is found, the line is ignored.
Analyzing Expressions
After it has determined the type of command contained in a command line (according to the above steps), SharkBase determines the contents of expressions contained in the command line.
Expressions are built up from variables and functions. Wherever SharkBase identifies an expression, it searches for the type of each element in the expression, in the following order:
1. Function 2. Numeric constant 3. String constant 4. System variable 5. Matrix variable 6. Redirected field (e.g., titian) 7. Field 8. Memory variable 9. Logical constant
You can see that memory variables are low on the list. This means, for instance, if you give a memory variable the same name as a field, say, LNAME, then at every mention of that memory variable, SharkBase will reference the field LNAME. Avoid such confusion by giving memory variables names that won't be confused with SharkBase keywords, functions, or field names.
Examples of Command Line Analysis
Here are some examples of how SharkBase analyzes command lines and expressions, and some guidelines for avoiding confusion.
EJECT=T
In this line, the first word is "EJECT". Since it is followed by "=", this line is interpreted as a STORE (notice that step 5, which calls for this interpretation, overrides step 4, which would have interpreted EJECT as a command). Next question: what is "T"? It is not a function, nor is it any of the other first six entries in the priority table above. If it is a field (priority 7) or memory variable (priority 8), EJECT is given the value contained in T. If it is neither, then "T" is interpreted as priority 9, a logical constant, true.
Therefore, this command line defines a variable EJECT whose content is the value of a field or variable, or the logical constant true.
IF eject
In this line, the first word is interpreted as a command (Step 4), and compiled as such (Step 8); EJECT, even though it is a SharkBase command verb, must in this context be a field or a memory variable, and there will be no confusion.
"Buried" Remarks
Many commands consist of a single word (e.g., EJECT and ENDDO). Whatever appears on a line following one of these commands is disregarded by SharkBase. For instance, you can write an IF structure like this:
IF approved .AND. count<100 <command sequence> ENDIF approved .AND. count<100
Here, the condition is repeated as a remark within the ENDIF command line to clarify which conditional structure is ended. This is a valid and useful remark; however, using ";" to separate remarks from commands is better practice:
ENDIF; approved count<100
Miscellaneous Command Line Guidelines:
1. Since SharkBase checks only the first four letters of command verbs, SET PRINT, SET PRINTER, SET PRINTERNOW are all the same.
2. Take care to write out in full those keywords that look alike when abbreviated. For instance, ENDD and ENDR are easily misread; such mistakes are difficult to find.
3. To sum up it is possible to use SharkBase keywords as variables and to place comments on command lines, if you are aware of all the above SharkBase conventions. However, to be on the safe side, avoid such practices.
A.8. Compiling Multiple Subroutines
In programs that call multiple subroutines, it is easy to get so bogged down in compiling the main (or "calling") program that your subroutines never get debugged. Imagine, for example, that you have a program MAIN.PRG, that calls 45 separate subroutines as follows:
DO subl <command sequence> DO sub2 <command sequence> • • • <command sequence> DO sub45 . . .
Normally, when you compile main, SharkBase has to compile SUB1PRG, SUB2.PRG, and so on, up through SUB45.PRG. If you are trying to debug SUB45, this will slow you down considerably. The command SET DO takes care of this problem. With SET DO ON (the default) the compiler compiles all subroutines along with the calling program. With SET DO OFF, compiling main does not compile the subroutines. Instead, for each subroutine SharkBase creates an "environment file", with the name of the subroutine file and the extension ENV. For example, the environment file for SUB45.PRG is SUB45.ENV. Once environment files exist, the subroutines can be individually compiled and debugged. SharkBase uses the environment files for the compilation of each subroutine. With SET DO OFF, you can still compile main so that the subroutines are compiled as overlays. To do so, use the LINK keyword in the COMPILE command:
COMPILE main LINK
Steps in Debugging Subroutines:
Here's an example of using SET DO OFF for debugging a subroutine.
1. Reset the DO switch:
SET DO OFF
2. Compile the main program:
COMPILE main
3. Compile any other subroutines without which the subroutine can't be run, e.g.:
COMPILE sub1 COMPILE sub10
4. Compile the subroutine you are debugging:
COMPILE SUB45
5. Run the main program:
DO main
Test whether SUB45 works properly. If it does not, edit SUB45.PRG, compile SUB45 again, then test it by executing MAIN.
A.9. Data-File Headers
On disk, a data file starts with a data-file header that describes the structure of the data file. SharkBase uses the data file headers to set up the data file table.
SharkBase supports four separate type of data files as follows:
Type 0 - An efficient file type not compatible with any older version of VP-Info/dBase/Clipper and other database languages. Type 0 files can have up to 4 billion records and up to 500 fields.
Type 1- Compatible with VP-Info Type 1 files.) Type 1 files can have up to 65,535 records and up to 500 fields.
Type 2 - Compatible with dBASE II data files, and are limited to 65,535 records and 32 fields.
Type 3 - Compatible with dBASE III, dBASE III+ and dBASE IV data files, and is the most flexible dbf file type. Type 3 files can have up to up to 4 billion records and up to 500 fields in SharkBase, although dBASE III and dBASE III+ cannot read a data file with more than 120 fields, and dBASE IV cannot read a data file with more than 255 fields.
Type 0 and Type 3 are the most capable and powerful dbf data file types, suitable for the largest scientific/census-size research projects.
File types 1 and 2 can now be considered obsolete, since they are limited to about 65,000 records. Type 3 should be specified when you need to use the data in Clipper, FoxPro, dBASE III or dBASE IV; this type uses twice as much disk space for the file header as SharkBase's newer Type 0. Type 3 is the default. The data-file headers of all four types of SharkBase data files contain essentially the same data; the main difference is file size and import flexibility.
SharkBase is agnostic when it comes to reading and writing any known dbf data file. When writing a dbf file, Shark automatically saves correctly without any additional user input. When creating a dbf data file in Shark, the dbf file type is selected when the file is created and saved:
Additional trivia: When importing/exporting data from common spreadsheets such as Excel or OpenOffice, it's a good idea to check beforehand to verify how the spreadsheet is handling dbf files and which Type is expected. You should be aware of which dbf Type your spreadsheet has been constructed. A quick import/export exercise will show which of the above Types is expected. This a normal caution since no spreadsheet maker wants to admit they're using an old data structure! Fortunately, Shark can switch Types at will.
Save this file as Type 0, 1, 2 or 3 ... (select)
From then on, Shark automatically recogizes the original data type, and no further attention is needed. Mind you, some experimenting may be called for when importing data files from older or non-Shark systems!
Data File Header technical details:
The following information is likely of interest only to data-repair enthusiasts! It's not essential for the average database programmer.
Type 0 Data File Header:
Introduction: Byte 0 File type indicator (CHR(0)) Bytes 1-4 Number of records in file Bytes 5-6 Location of first byte of first record Byte. 7-8 Length of each record Field 1: Bytes 9-19 Field name Byte 20 Type (C, N, or L) Byte 20 Width Bytes 22-23 Offset Byte 24 Decimal places Fields 2 and up: Add (<field number>-1)•16 to locations shown for Field 1. For example, add 16 to each byte in Field 1 for the location of the corresponding information for Field 2; thus, Field 2's name is found in bytes 25-35. A carriage return in the first byte of a location allocated for a field name indicates that the data file contains no more fields. First byte of first record is specified in Bytes 5-6.
Type 1 Data File Header:
Introduction: Byte 0: File type indicator (CHR(1)) Bytes 1-2: Number of records in file Bytes 3-4: Location of first byte of first record Byte 5: Not used Bytes 6-7: Length of each record Field 1: Bytes 8-18: Field name Byte 19: Type (C, N, or L.) Byte 20: Width Bytes 21-22: Offset Byte 23: Decimal places Fields 2 and up: Add (<field number>-1)*16 to locations shown for Field 1. For example, add 16 to each byte in Field 1 for the location of the corresponding information for Field 2; thus, Field 2's name is found in bytes 24-34. A carriage return in the first byte of a location allocated for a field name indicates that the data file contains no more fields. First byte of first record: Byte specified in Bytes 3-4.
Type 2 Data File Header:
Introduction: Byte 0 File type indicator (CHR(2)) Bytes 1-2 Number of records in file Bytes 3-5 Not used Bytes 6-7 Length of each record Field 1: 8-18 Field name Byte 19 Type (C, N, or L) Byte 20 Width Bytes 21-22 Offset Byte 23 Decimal places Fields 2 to 32: Add (<field number<-1) 16 to locations shown for Field 1 (see Type 1 example). First byte of first record: Byte 521.
Type 3 Data File Header:
Introduction: Byte 0 File type indicator (CHR(3) or CHR(131)) Bytes 1-3 Not used Bytes 4-7 Number of records in file Bytes 8-9 Location of first byte of first record: Not used Bytes 10-11 Length of each record Bytes 12-31 Not used Bytes 32-42 Field name Byte 43 Type (C, N, L, D, M, or F) Byte 44-45 Offset Bytes 46-47 Not used Byte 48 Width Byte 49 Decimal places Bytes 50-63 Not used Fields 2 and up: Add (<field number>-1) *32 to locations shown for Field 1 (see Type 1 example). First byte of first record: specified in Bytes 8-9.
Some additional "dbf Trivia":
Note that older Type 3 data files as implemented in dBASE have two unnecessary field types not present in SharkBase. The "Date" type is treated as an ordinary character-type field by SharkBase, and the Float type introduced with dBASE IV is treated as an ordinary numeric field in Shark.
In all cases, numeric values are stored in a form that is best handled with SharkBase's CHR( and RANK( functions, or with CTONUM( and NUMTOC(. If the number is longer than one byte, the value in the first byte is ones, the values in the second are 256s, the values in the third are 65536s, and so on.
For example, if you find that the values of Bytes 1 and 2 of a Type 2 file are 38 and 2, you could calculate that the data file has 38 +(2*256), or 550 records. If you need to convert the number 550 into a two-character string in SharkBase, your result would be NUMTOC(2,550).